
This project forecasts customer churn for a banking institution using multiple machine learning models and advanced analytics. The goal is to identify at-risk customers and inform data-driven retention strategies.
Project Overview
This end-to-end analytics solution combines business understanding with technical rigor. Classification algorithms—including Logistic Regression, Random Forest, XGBoost, LightGBM, CatBoost, and Neural Networks—were evaluated using a real-world dataset. The analysis addresses data imbalance with SMOTE, and applies feature engineering and selection to improve predictive power.
Business Insights
Why churn matters: Customer churn represents lost revenue and increased acquisition costs. Proactively identifying churn drivers helps optimize retention actions.
Key findings: German customers show the highest churn risk (as revealed by Chi-Square analysis), while gender is a significant demographic predictor.
Feature: geography_Germany, Chi2 Score: 5809.742503899883
Feature: Gender, Chi2 Score: 1997.6138770920807
Recommendations: Launch Germany-specific retention initiatives, and design gender-targeted offerings to boost loyalty.
Analytical Approach
Data cleaning and categorical encoding
First, the dataset was carefully examined for irrelevant or potentially misleading information. Key columns like customer ID and surname were removed to prevent leakage. The dataset also contained several categorical variables like Gender and Geography, which required encoding. Binary encoding was applied to Gender, and one-hot encoding to Geography for France, Germany, and Spain. Numerical features were scaled using robust and standard scalers to mitigate outliers’ effect and normalize the data.
df.drop(['CustomerId','Surname'], axis=1, inplace=True)df = pd.get_dummies(df, columns=['Geography'], drop_first=True)df['Gender'] = df['Gender'].map({'Male': 0, 'Female': 1})Addressing class imbalance
Bank churn is a classic imbalanced classification problem where customers who leave are fewer in number.
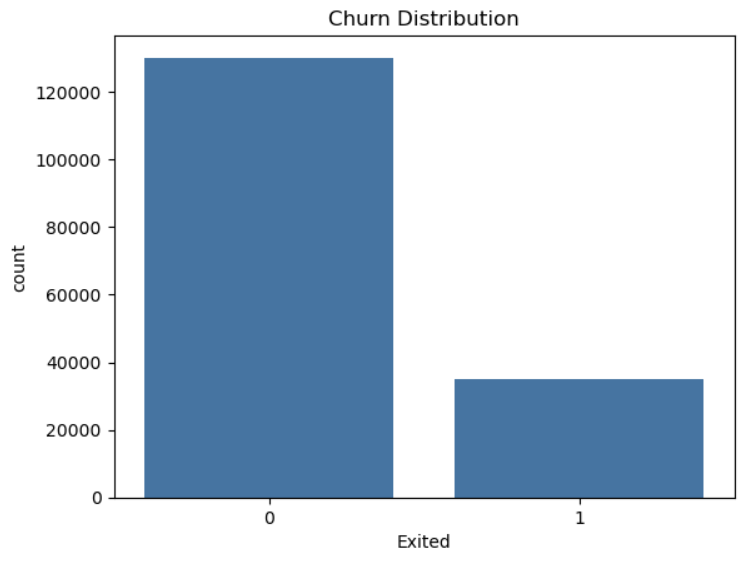
To address this, SMOTE (Synthetic Minority Oversampling Technique) was used to generate synthetic examples of the minority class, balancing the dataset and boosting model sensitivity to churners.
from imblearn.over_sampling import SMOTEsmote = SMOTE(random_state=42)X_res, y_res = smote.fit_resample(X, y)Feature engineering and selection
We used statistical tests like Chi-Square to understand feature importance, particularly focusing on categorical features. Geography and Gender emerged as strong churn predictors. These insights guided the feature selection process to optimize model performance.
Output Example for Chi2 Scores:Geography_Germany: 5809.74Gender: 1997.61Geography_France: 1211.56Geography_Spain: 337.37Model building and evaluation
Multiple classification algorithms—Logistic Regression, Random Forest, XGBoost, LightGBM, CatBoost, and Neural Networks—were systematically trained and evaluated. Performance was compared across accuracy, F1-score, and ROC-AUC to identify the best performer. LightGBM showed the highest balanced metrics with 86.18% accuracy and 88.83% ROC-AUC, followed closely by CatBoost and XGBoost.
| Model | Accuracy | F1-Score | ROC-AUC |
| LighGBM | 86.18% | 65.76% | 88.83% |
| CatBoost | 86.48% | 64.81% | 88.80% |
| XGBoost | 85.86% | 65.45% | 88.56% |
| Random Forest | 84.52% | 63.30% | 86.97% |
| Neural Network | 82.13% | 63.64% | 87.48% |
| Logistic Regression | 75.55% | 55.93% | 81.59% |
