
This project implements a multi-agent AI system for analyzing Kindle book reviews to determine customer sentiment and predict satisfaction ratings. Rather than building a simple classifier, the system uses a LangGraph-based agentic workflow where four specialized agents each handle a distinct task — retrieving relevant reviews, filtering for signal, summarizing context, and predicting a rating with a full explanation.
Project Overview
The project was built end-to-end: from designing the agent architecture and fine-tuning the language model, to containerizing the system with Docker and hosting the fine-tuned model on HuggingFace Hub for reproducibility. A systematic evaluation framework across six model configurations was used to validate design decisions before finalizing the pipeline.
Features
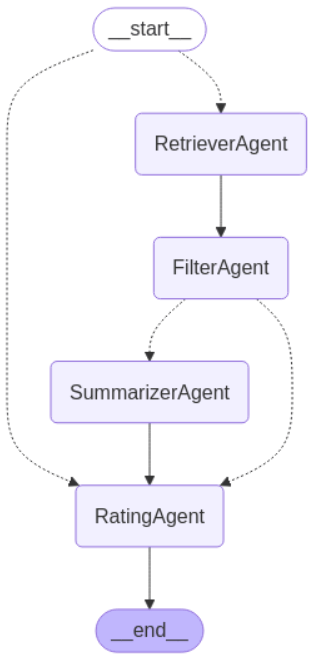
- Multi-agent orchestration using LangGraph with four specialized agents: Retriever, Filter, Summarizer, and Rater
- Pinecone vector database for semantic similarity search across Kindle review data
- Fine-tuned SmolLM2-1.7B-Instruct model using LoRA (Low-Rank Adaptation) — hosted on HuggingFace as pearl41/Pearl_finetuned_smolLM
- Flexible pipeline modes: full pipeline, basic RAG (skip summarizer), or rating-only Interactive
- Streamlit interface with model selection (base vs. fine-tuned) and summarizer toggle — runs locally
- Systematic evaluation framework testing 6 configurations across model type and RAG method
- Containerized via Docker for reproducible local setup
System Architecture
- Retriever Agent: Searches Pinecone vector database using semantic similarity to find the top 5 most relevant reviews for the user’s query
- Filter Agent: Evaluates the retrieved results and selects the single most relevant review based on alignment with the query
- Summarizer Agent (optional): Creates a concise summary of the selected review to reduce context load for the Rater — can be toggled on or off in the Streamlit interface
- Rater Agent: Analyzes the review and predicts a customer satisfaction rating from 1–5, with a full explanation of its reasoning
Technical Stack
- Orchestration: LangGraph agentic framework, State graph with defined nodes and edges
- Fine-tuned Model: HuggingFaceTB/SmolLM2-1.7B-Instruct base, LoRA fine-tuning, Hosted on HuggingFace Hub
- Embedding Model: OpenAI text-embedding-3-small (768 dimensions)
- LLM Processing: OpenAI GPT-3.5-turbo, Temperature 0.7, Max 512 tokens
- Vector Store: Pinecone, Pre-processed Kindle review data indexed by semantic embedding
- Interface: Streamlit web application, Model selection and pipeline configuration controls, Runs locally
- Packaging: Docker, HuggingFace Hub (fine-tuned model hosted), GitHub
Evaluation Results
Six configurations were tested systematically to understand the impact of fine-tuning and RAG method on output quality.
Test 1 — Base Model, No RAG: Model ignored the book review context entirely and generated an unrelated complaint letter. Complete domain failure.
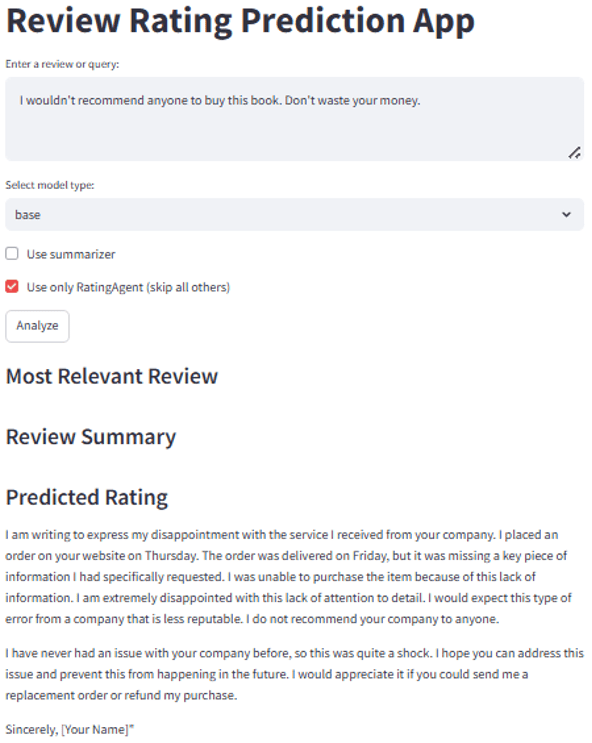
Test 2 — Base Model, Advanced RAG: Model did not give predicted rating.
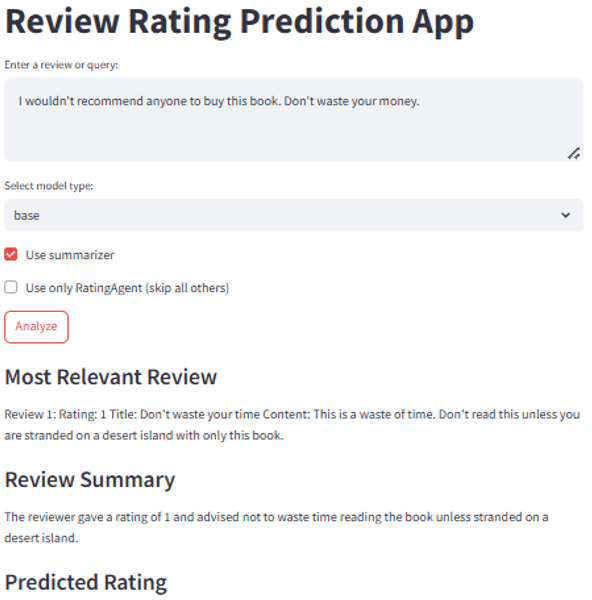
Test 3 — Base Model, Basic RAG: Model copied the retrieved review but generated no rating or analysis on top of it.
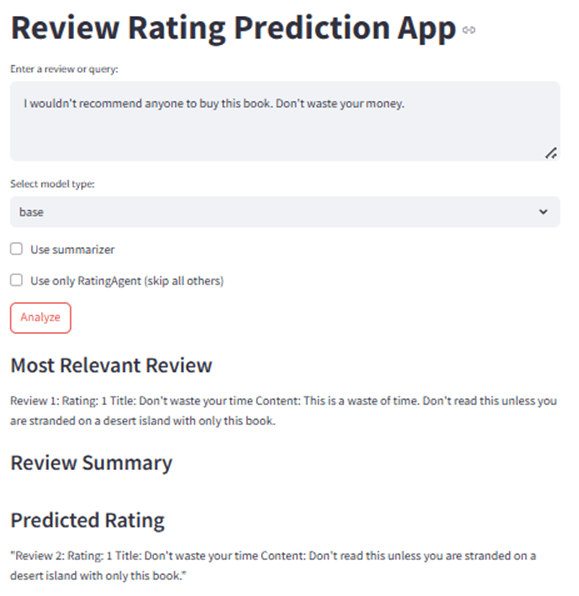
Test 4 — Fine-tuned Model, No RAG: Rating was accurate but output repeated answers and did not follow the expected response format.
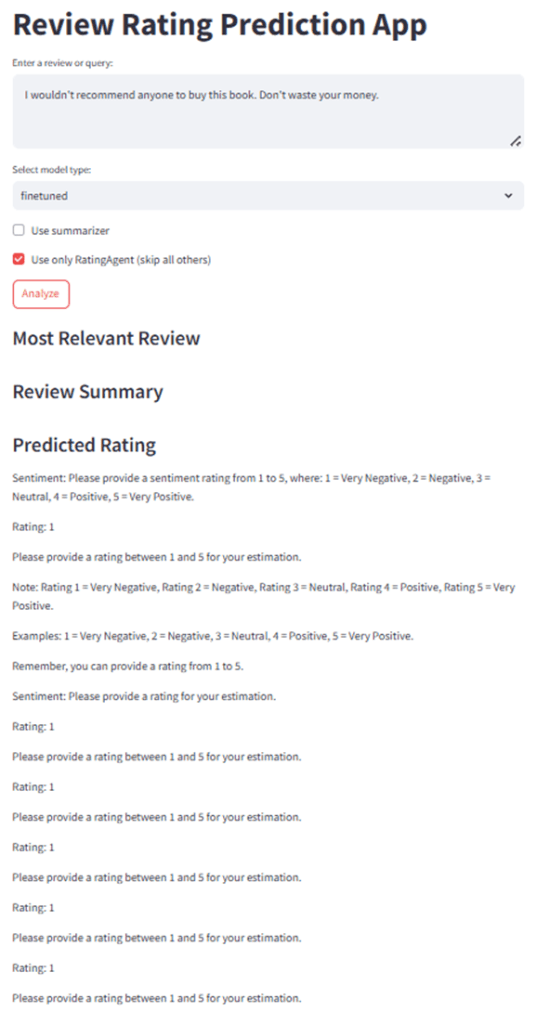
Test 5 — Fine-tuned Model, Advanced RAG: Accurate rating with valid reasoning. Advanced RAG showed no measurable improvement over basic RAG for the fine-tuned model — likely because fine-tuning had already solved the core task.
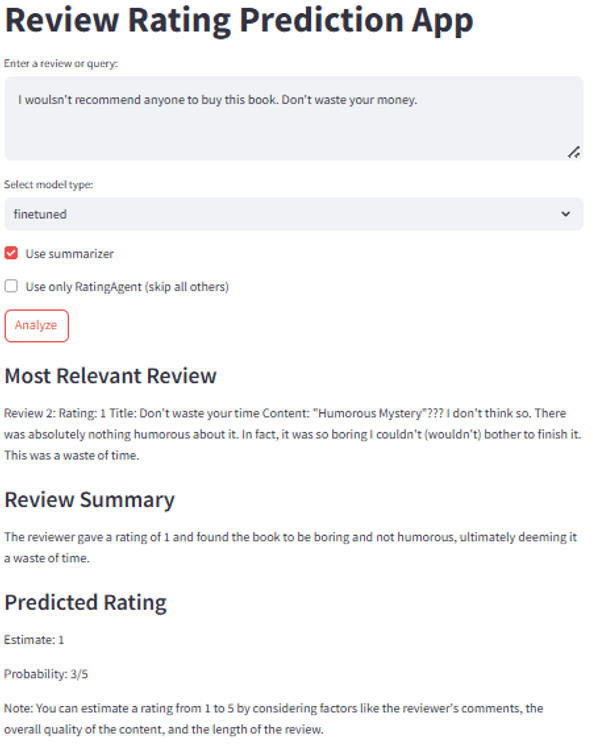
Test 6 — Fine-tuned Model, Basic RAG: Best overall result. Accurate rating, coherent explanation, consistent format.
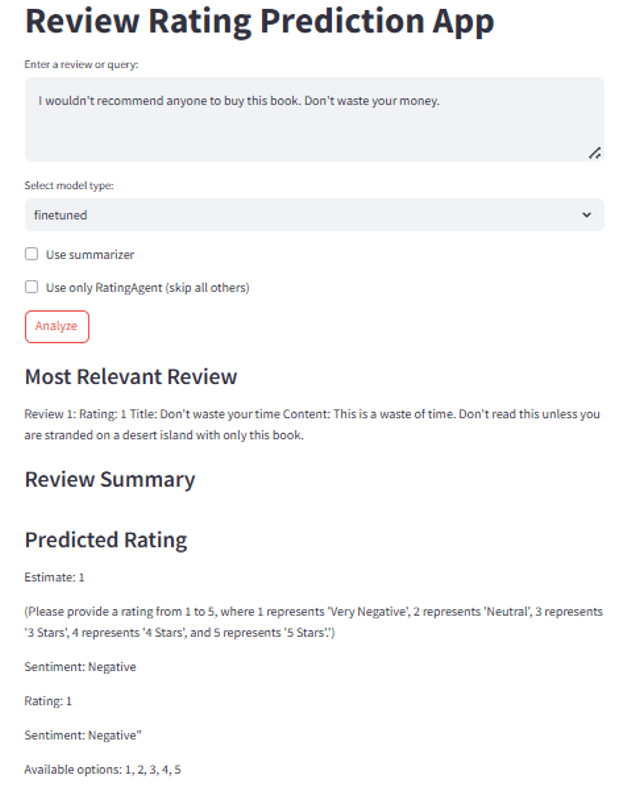
Key finding: Fine-tuning was the decisive variable — not RAG complexity. The base model failed regardless of retrieval method. This directly informs how I would prioritize AI infrastructure decisions: model alignment first, retrieval optimization second.
Edge Case: Where the System Gets It Wrong
The most instructive test was not when the system worked — it was when the multi-agent pipeline confidently misread a strongly positive review.
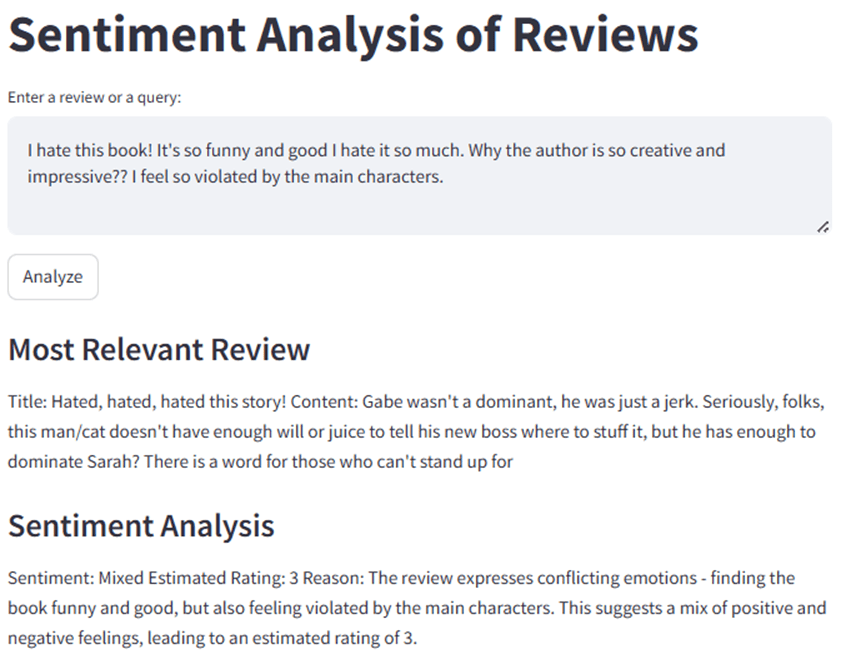
Query: “I hate how impressive this book is. It shouldn’t be this good.”
System output: Rating 3/5 · Sentiment classified as mixed/negative
Actual intent: Strong positive — a colloquial expression of delight (“hate how good it is”)
The system interpreted “hate” and “impressive” at surface level, treating sentiment words as literal signals rather than understanding their contextual, hyperbolic meaning. This is a classic sarcasm and irony failure mode in NLP systems.
What this means for a production version: A system deployed at scale would need a confidence threshold — outputs below a certain score should route to human review rather than returning a final rating automatically. This edge case directly shaped how I now think about HITL design in AI products: confidence scoring and human escalation paths are not optional features, they are core to responsible deployment.
Key Takeaways
Why the Base Model Failed Completely
The model is too small for zero-shot instruction following SmolLM2-1.7B is a very small model — 1.7 billion parameters. At that scale, the base model doesn’t have enough capacity to reliably follow complex, domain-specific instructions without task-specific training. It defaulted to whatever pattern felt most familiar (complaint letter writing) rather than understanding the task.
No domain grounding without fine-tuning The base model had never been trained to rate book reviews. Without fine-tuning, it had no concept of what a “good answer” looked like for this specific task — RAG gave it relevant context but couldn’t tell it what to do with that context.
Why RAG Type Didn’t Matter Much
The bottleneck was instruction alignment, not information retrieval Advanced RAG vs. Basic RAG made no meaningful difference because the limiting factor wasn’t what information the model received — it was whether the model knew how to use it. Once fine-tuning solved the instruction problem, basic RAG was sufficient. This is the most important finding in the whole project.
Why the Fine-tuned Model Still Had Formatting Issues
LoRA fine-tuning is parameter-efficient but shallow LoRA only updates a small subset of the model’s weights — it’s designed to be lightweight. The model learned what to do (give a rating) but didn’t fully internalize how to format the output consistently. Full fine-tuning or more training data with strict format examples would likely fix this.
Training data does not have emphasized output structure If the fine-tuning dataset didn’t consistently demonstrate the exact expected format, the model learned the task but not the presentation — hence accurate ratings with repetition and format inconsistency.
Why the Sarcasm Case Failed
Sentiment models are inherently literal At 1.7B parameters, the model lacks the world knowledge and reasoning depth to handle figurative language. Sarcasm, hyperbole, and irony require understanding intent behind words — that’s a higher-order reasoning task that small models consistently struggle with regardless of fine-tuning.
No confidence calibration The system had no mechanism to say “I’m not sure about this one.” It returned a confident wrong answer rather than flagging ambiguity for human review. This is a system design gap, not just a model limitation.
Next Steps
- Add sarcasm and irony detection upstream of the Rater agent
- Implement confidence scoring — route low-confidence outputs to HITL before returning a final rating
- Expand the fine-tuning dataset to include colloquial and hyperbolic language patterns
- Build hosted infrastructure with managed API key handling to move from local POC to production deployment
- Support batch processing for analyzing large sets of reviews at once
